This blog post was originally posted on Eira Tansey’s website.
Why We Should Consider a Change
As archivists enter our second summer of online conferencing, and the pandemic has gone from “getting under control” with the vaccine rollout to “?????? who knows???” with the variants, people are naturally wondering what conferencing in the future will look like if, and when, it is safe to travel again. We should not go back to the pre-pandemic conference model. We should retain the best of both online and in-person conferencing, and not squander the incredible opportunity we have to rethink how we conference.
One of the blessings and the curses of the archives profession is how incredibly decentralized it is. Many, if not most, archivists belong to multiple location and specialty-based associations. For example, an archivist could belong to a local (Greater New Orleans Archivists), state (Society of California Archivists), regional (Midwest Archives Conference), national (Society of American Archivists), and/or specialist organization (Association of Moving Image Archivists). As a result, it is not unusual for archivists – particularly those with financial privilege or institutional support – to maintain memberships in multiple archival associations. But all of these organizations are independent of one another – which also means all of their annual meetings are coordinated independently of one another.
This is not sustainable, on multiple levels. It’s certainly not sustainable on a carbon emissions level, and given the limited travel budgets of most archivists (many in our profession have to pay entirely on their own dime), archivists have always had to choose which conferences to attend and which to skip (I have no evidence to support this, but I wouldn’t be surprised if attendance at regionals increases in the years that SAA is farthest away from that region). Even for those of us with institutional travel support, it is likely that our travel budgets will take a hit in the future, or certainly will not keep up with costs.
After attending a number of online conferences this year that were traditionally held online, I have been hearing the following comments about the future of conferencing:
- “For years I could not attend this conference due to caregiving obligations/disability concerns, and now that it’s online I can finally participate.”
- “I like the ease of conferencing from my desk but I also get interrupted by work all the time because I’m still at the office instead of in a conference hotel.”
- “I can actually afford to attend as a low-income archivist because I don’t have to pay for a flight and hotel.”
- “I enjoy the online sessions but I miss the in-person contact with colleagues from other institutions who are a major part of my professional support network”
All of these concerns are important and valid. We have to take them seriously and not pit them against each other. Presenting the future of conferencing as in-person vs. online is a false choice, because there is a hybrid model we can begin preparing the groundwork for today if we are serious about creating an equitable and sustainable profession.
Learning from the Nearly Carbon Neutral and Distributed Models
Prior to the COVID-19 pandemic, a conference model called the Nearly Carbon Neutral (NCN) approach started circulating in humanities academic subdisciplines. The genesis for the first NCN conference in 2016 arose out of the recognition that academics who take long-haul flights even just a couple times a year for conferences incur significant carbon footprints.
The original Nearly Carbon Neutral approach is very much based on a primarily online model of pre-recorded lectures with interactive Q&A, but subsequent iterations of the NCN model developed a local node distributed system: “sites of collective, face-to-face engagement with the virtual conference.” This was used for the 2018 conference of the Society for Cultural Anthropology (SCA). In their fascinating and comprehensive post-conference reflections post, the SCA organizers noted that their traditional biennial conference typically drew 200 mostly US attendees, but the distributed approach brought in over 1,300 people from 40 countries with 50 local gathering nodes. Due to the international level of participation, the conference organizers had to figure out how to schedule the sessions across time zone differences and create a web presence that could sustain 24/7 access needs.
The SCA organizers ran some back of the envelope math about how much energy was saved from their 2018 experiment:
[A] conservative estimate of the environmental benefit of this experiment is about 425 tons of emissions saved. According to the Environmental Protection Agency, that’s about the same as 100 cars driven for a year. It’s like taking 11,500 cars off the road for the duration of the three-day conference. Go anthropologists!
A proposal for HACS: Hybrid Archives Conference Strategy
Archivists are already highly networked through existing local/state/regional groups, which provides us with fertile ground to experiment with a distributed/hybrid/decentralized conference model. While the local/state/regionals are independent from the Society of American Archivists, there have been efforts in recent years to develop some coordination among these organizations, most notably through the Regional Archival Associations Consortium (RAAC):
The Regional Archival Associations Consortium (RAAC) provides a mechanism to connect the leadership of regional, multistate, state, and local archival organizations with each other and to the Society of American Archivists (SAA). RAAC seeks to facilitate information exchange and foster collaboration among these organizations. It offers formal channels to coordinate efforts intra-state, interstate, and with SAA which facilitate streamlining actions, reducing costs, and increasing services.
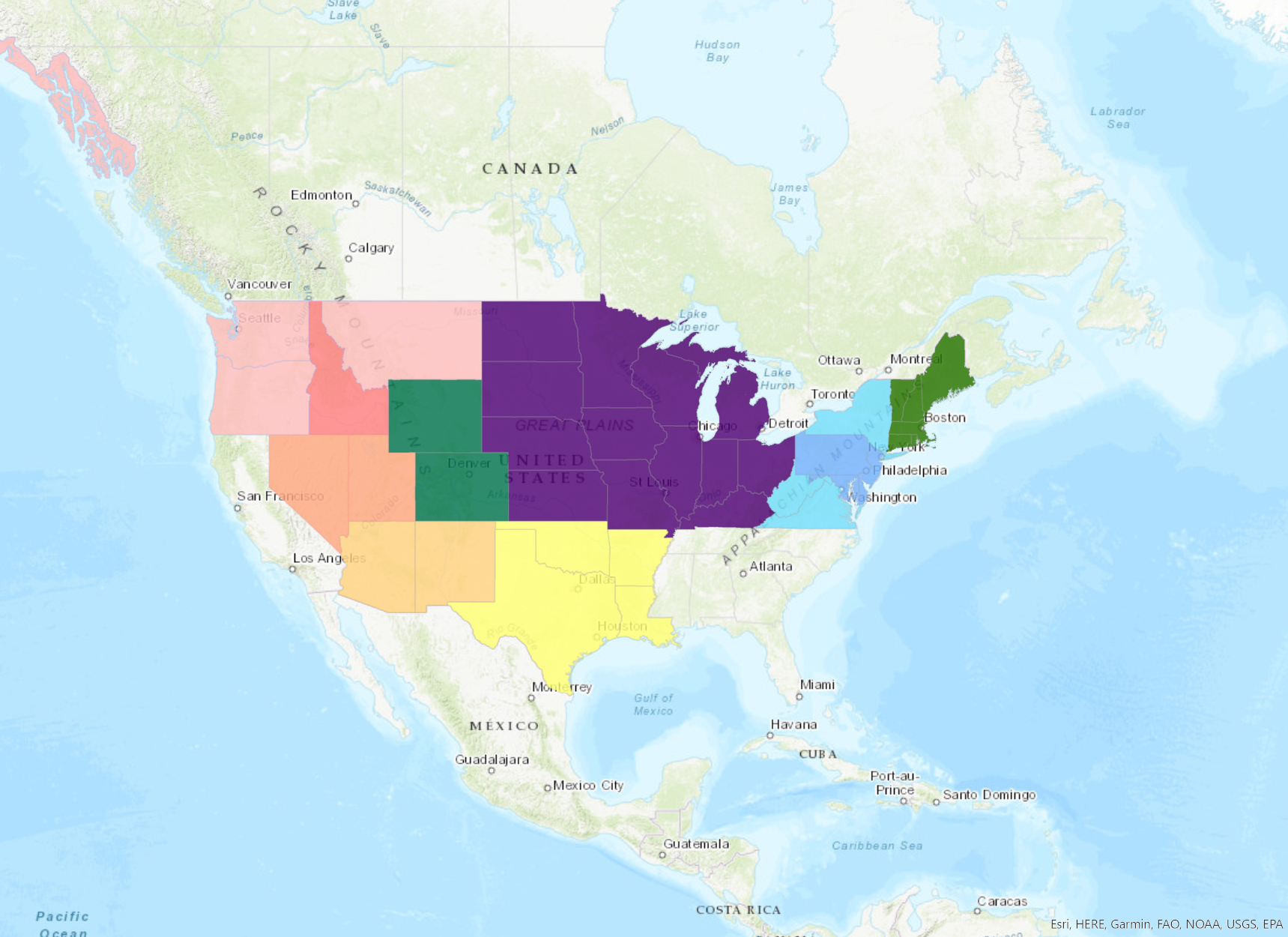
The regionals are a natural way to site nodes for a distributed and decentralized hybrid conference model. Let’s take a look at what the map of our regionals looks like right now. This is a little confusing, because some states are part of more than one regional organization, especially in the Conference of Inter-mountain Archivists and Society of Southwest Archivists (for example, New Mexico and Arizona are both part of SSA and CIMA), as well as the Mid-Atlantic Regional Archives Conference and Delaware Valley Archivists Group regions. But the tl;dr is that if a state in this map is colored in, it is part of one of the following 8 regional organizations:
- Conference of Inter-Mountain Archivists
- Midwest Archives Conference
- New England Archivists
- Society of Southwest Archivists
- Mid-Atlantic Regional Archives Conference
- Northwest Archivists
- Society of Rocky Mountain Archivists
- Delaware Valley Archivists Group
For our pilot conference model, let’s pick 10 node cities:
- Miami
- Boston
- Washington DC
- Chicago
- Dallas
- Salt Lake City
- Los Angeles
- Portland
- Atlanta
- Albuquerque
…if you draw a buffer of 350 miles out from every city, you can see how much of the country is covered.
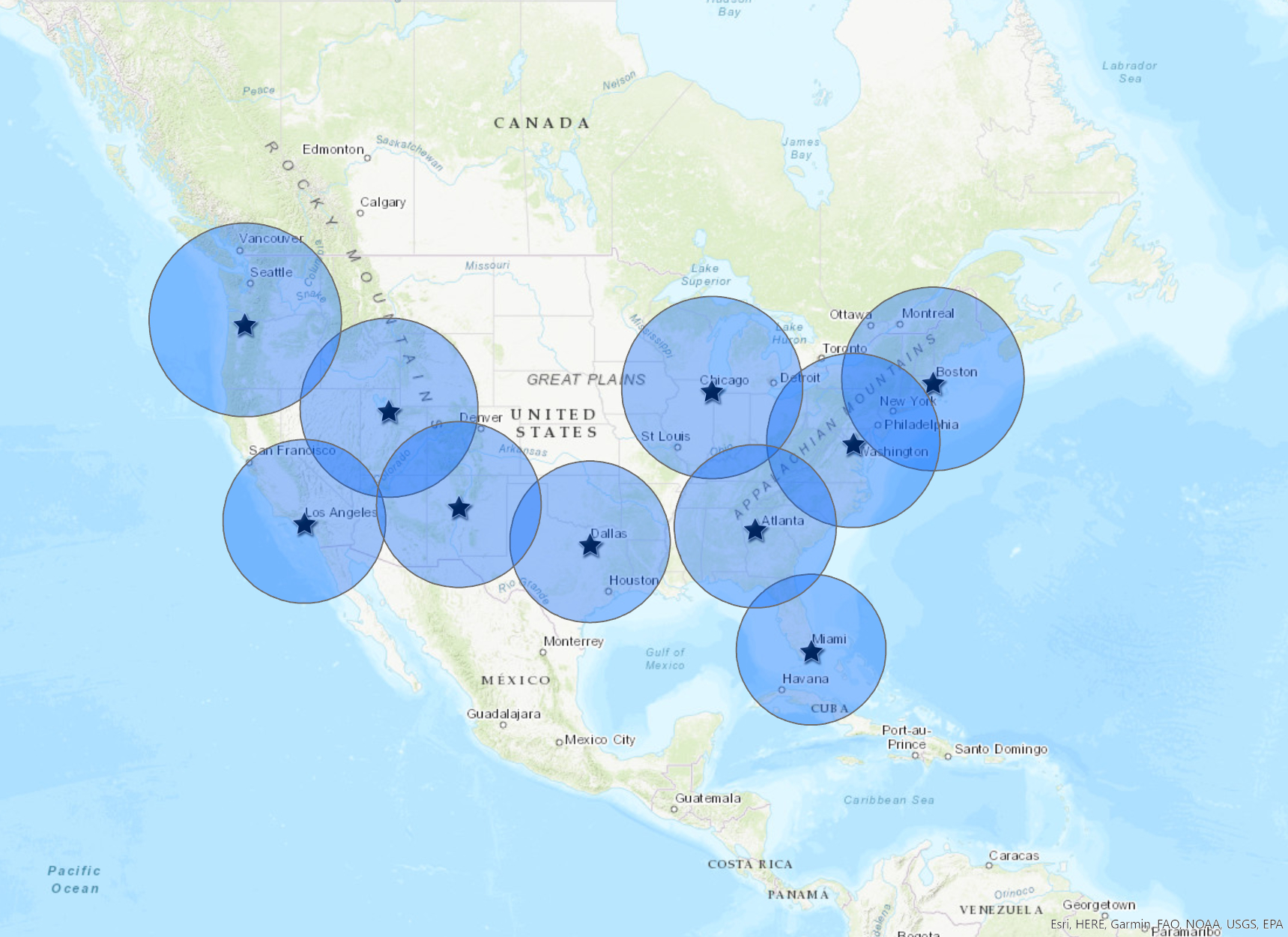
If you want to noodle around with these maps, you can access a public version to play around with them. Note that not all of these nodes are within an existing regional organization, but every state that is not in a regional has its own state-level association. So for example, Miami, Atlanta, and Los Angeles would be respectively covered by the Society of Florida Archivists, Society of Georgia Archivists, and Society of California Archivists (again, for the non-archivists out there, even though all of these names sound suspiciously similar to “Society of American Archivists” they are all independent autonomous groups with no official subordinate relationship to the SAA).
Any good pilot project deserves an acronym, so how about HACS: the Hybrid Archives Conference Strategy. It already sounds a lot like another acronym we’re already familiar with. There are infinite iterations you could come up with for a hybrid schedule, and the following is just one example. In our example, SAA and the regionals essentially combine forces into a 3-day hybrid conference.
My extremely half-baked ideas on some guiding principles:
- Ideally, all nodes are roughly equivalent in terms of anticipated audience, registration costs, and programming offerings, though one may need to serve as the “command center” for technology purposes and hosting things where SAA staff may need to be on-site (e.g. Council meetings and the annual business meeting). This may need to be Chicago given that its where the SAA offices are headquartered. Care should be taken so that the command center doesn’t simply default to being the conference location everyone wants to go to and defeating the point of a distributed model.
- Nodes should be located in cities that support multi-modal transportation, including rail.
- All nodes should offer on-site childcare. For more about the importance of childcare provision at archives conferences, please see “The Cost of Care and the Impact on the Archives Profession” by Braun Marks, Dreyer, Johnson and Sweetser.
- Roughly half of the overall programming would be overseen by SAA (“national”) and half would be overseen by the state/regional organizations (“local”). A roughly equal mix of nationally-selected and locally-selected programming would be offered at each node.
- Presentation proposals could be sent to either the national or a local program committee for consideration. Topics of a broad national interest should be sent to the national program committee, while institutional case studies or highly localized topics should be sent to a local program committee.
- One challenge may be that a panel accepted by the national committee is more likely to have presenters from disparate regions. In this case, they may be encouraged to deliver their panel from the node closest to the majority of panelists or in special circumstances the panel itself may require hybrid delivery (half of the panelists in one location and half in another) or it may be a panel that is simply pre-recorded if the logistical concerns about getting everyone together are difficult to resolve.
- Any content from official nodes should default to streaming & recording online with interactive Q&A at the end to accommodate remote viewers unless there are good reasons to keep it offline (for example, confidentiality concerns, workshops with significant hands-on work meant for small in-person groups, etc)
- All conference registration will happen via nodes. Conference registration fees should be roughly similar at all nodes to incentivize minimal travel. In other words, you don’t want LA to be $400 and Albuquerque to be $50, because then more people might go to Albuquerque, thus defeating the point of a distributed model. This may require use of alternative non-hotel venues in some cities.
- All nodes would have at least some rooms dedicated to streaming in panels from other nodes.
- Anyone can register as a fully-remote viewer that enables access to all recorded sessions. Access to all recorded sessions will be automatically included in anyone who plans to attend via a node.
- People may set up unofficial nodes outside of the official nodes for the purposes of increasing viewership and accessibility by using their remote viewer registration (notice in the second map that there are major parts of the Plains states that are not well-served by the hypothetical set of nodes). However if the unofficial node hosts more than a couple viewers, they will be strongly encouraged to make an additional donation to the closest node to them to support the technology investment required for content delivery.
| Day 1 | Day 2 | Day 3 |
| Early AM: Local workshops and local governance meetings (for example, MAC’s business meeting) | Early AM: Conference sessions (50% selected by local program committees, 50% by national program committee) | Early AM: Conference sessions (100% selected by national program committee) |
| Late AM: Local workshops and local governance meetings (for example, MAC’s business meeting) | Late AM: SAA Plenary | Late AM: SAA committee and section meetings |
| Early PM: Conference sessions (100% selected by local program committees) | Early PM: SAA committee and section meetings | Early PM: SAA annual business meeting |
| Late PM: Conference sessions (100% selected by local program committees) | Late PM: Conference sessions (50% selected by local program committees, 50% by national program committee | Late PM: Conference sessions (100% selected by national program committee) |
Some Concluding Thoughts
I know that inevitably some people will consider this and immediately ask “OK sounds cool but what about….?” I’m sure there are plenty of contingencies I haven’t considered. But I hope that all the reasons I’ve laid out for why we should try this are compelling enough to give it a try.
One very obvious challenge of putting together something like this is that there is less time for stuff, and inevitably a lot of things will get cut that normally wouldn’t happen in the status quo environment of more conference time (4ish days for SAA, 2-3 days for regionals). And honestly, after serving on numerous governance and programming committees, this should be thought of as a good thing. Not only do I think that our conferencing model is unsustainable, I also think the vast array of committees and sections and working groups that exist across our national and regional organizations are unsustainable.
We archivists are very good at starting things, but we are very bad at letting things go. We can try to keep all of our conferences and organizations going at the same pace while finding fewer and fewer people each year who are willing to volunteer for new governance and conference planning roles. Worst case scenario, the institutions we work at will make that decision for us as our travel budgets are cut and our profession shrinks by attrition. Or we can avoid both of these less than ideal scenarios by preparing new ground to transform into something better than what we’ve always known. It is time to say goodbye to our old conferencing model, and begin preparing the ground for a much healthier, networked, and accessible conference culture.
Many thanks to Jenny Latessa in UC Libraries Research and Data Services for her explanation of how ArcGIS handles color-coding symbology.